INTRODUCTION TO VIRAL GENOMICS

@Canva
Glossary
- Adaptors: a short chemically synthesised single or
double-strand DNA (oligonucleotide) used in some sequencing
methodologies that allow the addition of a DNA barcode or other
oligonucleotides downstream of an unknown or amplified DNA strand.
- Amplicon: a DNA fragment that has been amplified
using polymerase chain reaction (PCR) or a method that results in the
generation of multiple copies of that fragment.
- A-tailing: an enzymatic reaction to add a sequence
of adenines at the 3’-terminus of a DNA fragment for sequencing
purposes.
- BAM: Binary version of a SAM file format.
- Barcoding: addition of a tag of known DNA sequence
(barcode) to an amplified DNA strand that permits sequencing multiple
samples in parallel, and stratifying sample data informatically
post/during sequencing.
- cDNA: complementary DNA, a DNA molecule synthesised
from an RNA molecule.
- COVID-19: coronavirus disease 2019.
- DNA: deoxyribonucleic acid is an information
molecule forming the “base code” for a living organism.
- Enzyme: a protein able to catalyse, i.e. accelerate
chemical reactions.
- Exome: part of genome composed of exons, i.e. the
sequences that will be transcribed and translated into proteins.
- FASTA: text-based format for representing nucleotide or peptide sequences, with base pairs or amino acids represented by single-letter codes.
- PCR: polymerase chain reaction (PCR) is a
laboratory technique for rapidly making (amplifying) millions to
billions of copies of a given section of DNA, which may then be analysed
further.
- Primer: a short chain of oligonucleotides used to
target and ‘prime’ the initiation of DNA replication.
- Protein translation: is the process of synthesising
proteins from a transcript.
- NGS: next-generation sequencing, a high throughput
sequencing methodology.
- Nucleotides: the individual subunits that form DNA
and RNA molecules.
- RNA: ribonucleic acid, an information molecule, can
be the “base code” for viruses.
- SAM: sequence alignment/map format. It is a TAB-delimited text format that holds information from sequence alignment.
- SARS-CoV-2: severe acute respiratory syndrome
coronavirus 2.
- SNP: single-nucleotide polymorphism is a nucleotide
substitution in a specific position of the genome. It is identified when
compared to a reference sequence.
- Sonication: is a technique that applies sound
energy to a sample at a specific amplitude. In molecular biology, it is
commonly used for fragment DNA fragmentation.
- Transcription: is the process of copying a segment
of DNA into RNA.
- Trimming: in bioinformatics, it is the process of
removing the ends of the reads, leaving only a region of high-quality
bases and those relating to the sample, not the sequencing chemistry or
DNA barcoding.
- VCF: variant call format, is the plain text file
format that holds gene sequence variations.
- Viral replication: is the mechanism in how viruses
propagate during the infection cycle, it is the process of virus
multiplication.
- Viral genome variant: a virus that has one or more
mutations in its genome.
- Whole-genome sequencing (WGS): is the method of determining the entirety, or almost the entirety, of an organism’s genomic DNA sequence all at once. This entails sequencing all of an organism’s chromosomal DNA, as well as, DNA found in mitochondria and, in plants, chloroplasts.
Frequently asked questions
Galaxy questions
Question 1: I cannot change the name of my history in
Galaxy.
Please make sure that you are logged in. If you click on the “User” tab
at the top, you should see “Logged in as [your_username]”
Question 2: I cannot find the tool you are referring to in
Galaxy.
Please make sure that you are logged in to the correct Galaxy instance.
There are many Galaxy instances such as: https://usegalaxy.eu/, https://usegalaxy.org/, https://africa.usegalaxy.eu, and
they do not all have the same tools.
Mapping
Question 1: Is mapping and aligning to a reference genome the
same?
They are often used interchangeably because they are often used for the
same purpose. But with mapping, we are trying to find the approximate
origin/location of a sequence. With alignment, we aim to find the exact
differences between two sequences.
Question 2: What is a read?
After sending your DNA/RNA sample to the sequencing facility, your
sample gets fragmented into many small fragments so that the sequencing
machine can handle it. These fragments are then copied and a camera
takes an image of each nucleotide, producing a stretch of letters ACGT.
This stretch of letters represents the nucleotides that were present in
your fragmented piece of DNA. This is also called a read.
Variant calling
Question 1: Is there a difference between variant calling and
variant annotation?
Variant calling is simply calling the position where a nucleotide(s)
differs from a reference genome. It also tells us how it is different,
by telling us which nucleotide was present in the reference genome and
how your sample differs. With variant annotation, we show the potential
downstream effect of that mutation. For example, if it was an SNP, was
it synonymous/non-synonymous. Did a mutation lead to a stop-loss, a
frame-shift etc?
SARS-CoV-2 replication cycle
Download the presentation slides here
In this video, you will be guided through the SARS-CoV-2 replication cycle. You will learn how the virus enters the cells and cause disease and details of how the virus makes copies of itself to infect other cells.
SARS-CoV-2 genomic landscape
All of us have been impacted in some way by SARS-CoV-2 (severe acute respiratory syndrome coronavirus 2). You are likely to be familiar with a city in China that you never heard of before the pandemic, Wuhan - where this virus was isolated in 2019.
SARS-CoV-2 is a single-stranded RNA virus of ~30 Kb (positive sense) (Figure 1). Despite being incredibly small, compared to the human genome, which is approximately 6 Gbp, SARS-CoV-2 is the largest known RNA virus. SARS-CoV-2 has a crown-like shape which contains four main structural proteins, namely the: spike (S), envelope (E) glycoprotein, nucleocapsid (N), membrane (M) protein, along with 16 nonstructural proteins, and 5-8 accessory proteins.
We are interested in the structure of a virus/organism because it gives us information about how the virus is able to shed, spread, infect and subsequently cause disease (pathogenesis).
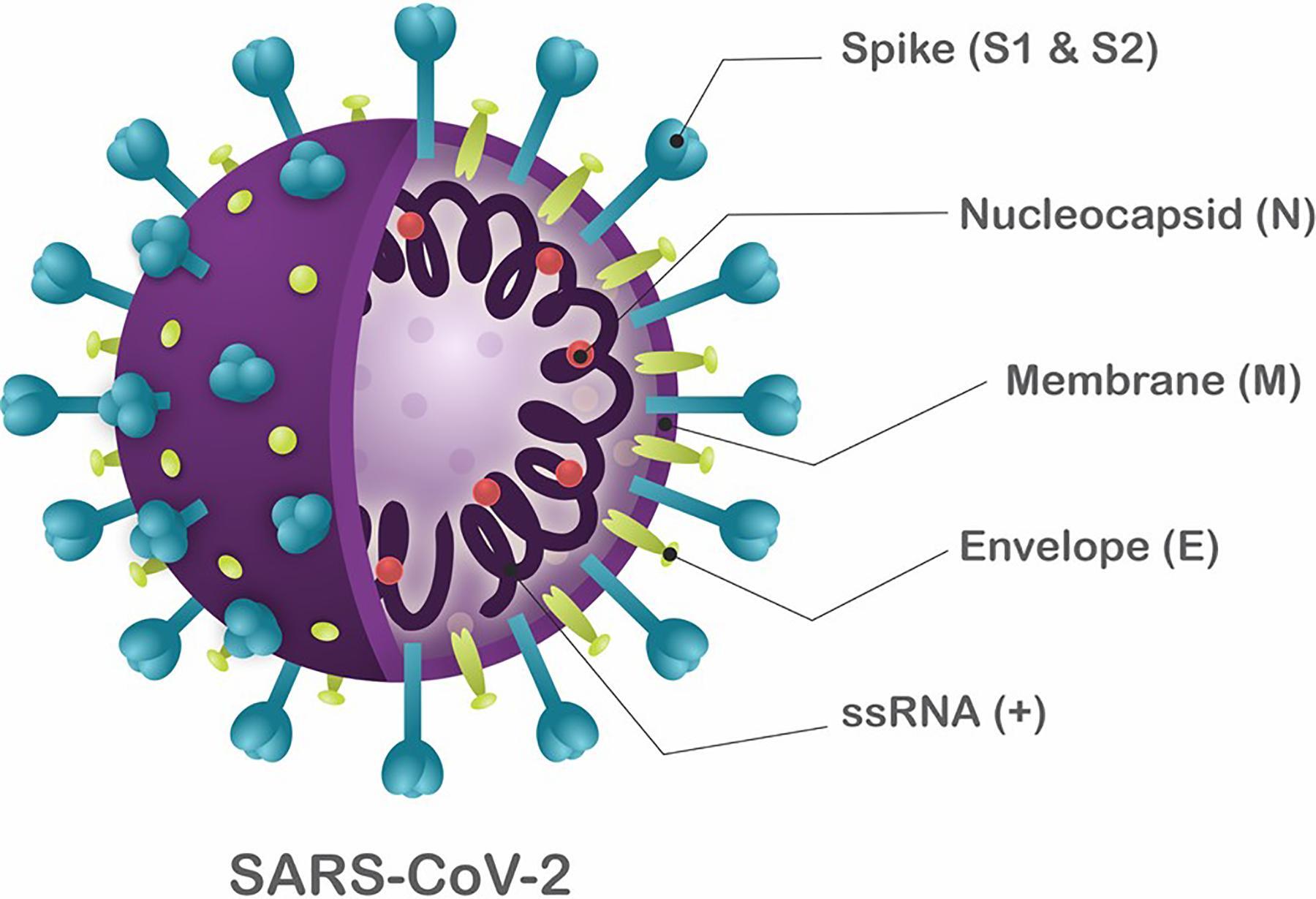
Source: Frontiers
Click here to enlarge the image
Download Figure 2 alt-text here
The accessory proteins participate in the viral replication, assembly and in virus-host interactions.
The non-structural proteins are like maintenance workers which act as enzymes, coenzymes, and binding proteins to facilitate the replication, transcription, and translation of the virus.
Finally, the structural proteins are essential for the host cells’ binding and invasion. The 3D shape of a spike protein is shown in Figure 2 below. This protein allows the virus to enter human cells by binding to human ACE receptors in the respiratory epithelium. This article provides a detailed explanation of this process.
Source: StatPearls Publishing LLC
Click here to enlarge the image
Download Figure 2 alt-text here
The spike proteins are also frequently the site of mutations, resulting in diverse new variants. Mutations are natural random events which occur in viruses during replication. A variant has one or more mutations that may allow it to be distinct in its transmissibility, virulence, pathogenicity or response to vaccines. Currently, variants have been grouped into four different categories which are: a Variant of Interest (VOI), a Variant Being Monitored (VBM), a Variant of High Consequence (VOHC) and a Variant of Concern (VOC). This article provides a detailed explanation of this process and you can read more about these proteins in here
A VOC usually contributes to outbreaks due to its increased transmission fitness and/or immune evasion ability. The most notable VOCs are currently called Alpha, Beta, Gamma and Delta; firstly described in the United Kingdom, South Africa, Brazil and India, respectively. The latest and most transmissible variant has been labelled Omicron, which was also first reported in South Africa. The location of where variants are first described is highly linked to the amount and quality of genomic surveillance occurring in a particular country. We can only find variants if we are looking for them at a genomic level.
The CDC’s website has up-to-date information to keep you abreast of the range of variants.
Mutations may also lead to the formation of new lineages. Lineages are described as being a genetically closely related group of viral variants which are derived from a common ancestor. Tracking lineages informs us of outbreaks and of the spread of a virus in a community or within populations.
Zoonotic coronaviruses have caused several outbreaks over the last two decades and many of the coronaviruses present in other mammals have the potential to infect humans. Therefore our continuous efforts to understand the origins and evolution of SARS-CoV-2 will remain critical.
Further reading
Features, Evaluation, and Treatment of Coronavirus (COVID-19)
CDC Coronavirus Disease 2019 (COVID-19)
Defining a New Strain of a Virus
Omicron: What Makes the Latest SARS-CoV-2 Variant of Concern So Concerning?
The Genomic Landscape of Severe Acute Respiratory Syndrome Coronavirus 2
SARS-CoV-2 Proteins: Are They Useful as Targets for COVID-19 Drugs and Vaccines?
Public Health Responses to COVID-19 Outbreaks on Cruise Ships — Worldwide, February–March 2020
COVID-19, a worldwide public health emergency
Antivirals Against Coronaviruses: Candidate Drugs for SARS-CoV-2 Treatment?
On the origin and evolution of SARS-CoV-2
Aerosol and Surface Stability of SARS-CoV-2 as Compared with SARS-CoV-1
Relationship between the ABO Blood Group and the COVID-19 Susceptibility
Overview of genomic, sub-genomic and anti-genomic sequences
During the lifecycle of SARS-CoV-2, varying genomic sequences contribute toward the creation of new virions. These virions (small, membrane-bound particles containing viral RNA) are formed within the infected host cell machinery, leading to a persisting infection whereby it is not cleared by the immune system and enables further host-cell entry. These genomic sequences can be categorised for simplicity into three key groups: genomic sequences, sub-genomic sequences and anti-genomic sequences.
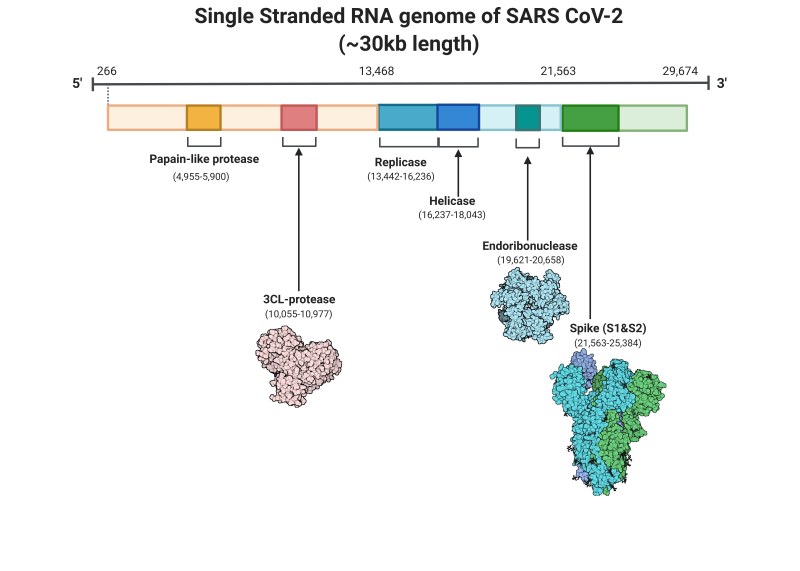
Genomic sequences
Genomic sequences, known as gRNA, consist of all of the genetic information needed to encode SARS-CoV-2 and its associated proteins. The organisation of this information varies between different viruses to generate different ‘classes’. SARS-CoV-2 is classed as a positive-sense single-stranded RNA virus, similar to that of common cold viruses where the genome is organised as a single contiguous RNA genome. This class of viruses produces unique sub-genomic RNA sequences as part of their life cycle (discussed below). The SARS-CoV-2 genome is 5′-capped and has 29,870 bases and a 3′ poly(A) tail of variable length. It encodes at least 13 recognised open reading frames (ORFs), each of which contains regions with specific functions key to the virus’ transcription, translation and replication. The coding elements of gRNA are hugged by a 5′ untranslated region (UTR) (265 nucleotides) and a 3′ UTR (337 nucleotides).
When a host cell is infected, gRNA synthesis occurs in double membrane-bound organelles (replicative organelles) within the cell. Utilising the original gRNA from the entered virion, the replicative-transcription complex (RTC) creates more gRNA sequences. This is achieved through anti-genomic sequences. These are complementary to the original viral genome and are created by the RTC to act as a minus-strand template. The minus-strand template then utilises complementary base pairing to form new positive-strand RNA sequences for new gRNA.
Anti-genomic sequences
Before new gRNA synthesis occurs, the anti-genome is created in these new replicative organelles – these are virally-induced membranes. The anti-genome is a full-length complement to the original gRNA and acts as the template for synthesis of the new gRNAs. After ‘transcription’ using the anti-genomic sequences, new gRNA can take one of three paths. The first could lead to the new gRNA being used to create new enzymes and accessory proteins key to viral replication within the cell. The second path is creating more new gRNAs. The third is that the gRNA could acquire a nucleocapsid shell, then a lipid bilayer membrane to form a new virion before leaving the cell (Figure 3).
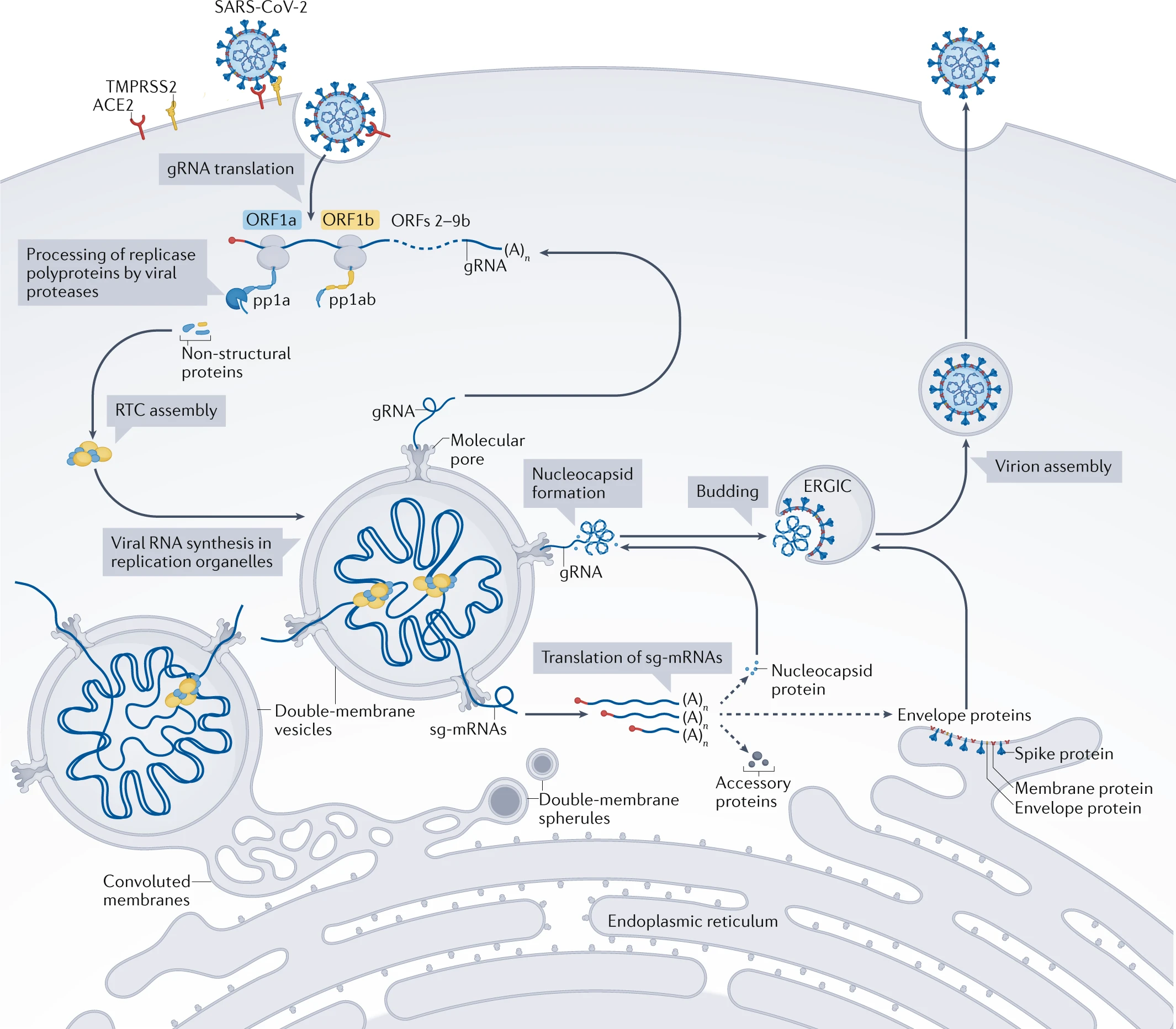
Source: Nature
Click here to enlarge the image
Download Figure 3 alt-text here
Sub-genomic sequences
Sub-genomic RNA sequences are a unique feature of positive-sense RNA viruses. These are produced by the discontinuous transcription of virion structural genes during active replication and result in the formation of rearranged template sequences that are not found in juxtaposition in the native RNA genome of the virus. The gRNA sequences found for these proteins are what is looked for in COVID-19 tests.
Whilst the anti-genome is being generated in replicative organelles, these smaller, minus-strand sgRNAs are also produced. These then originate a nested group of sg-mRNAs which are fundamental in the synthesis of structural proteins necessary for virion packaging, consisting of the membrane, spike, nucleocapsid and envelope proteins. The nucleocapsid protein in particular is acquired by newly formed gRNAs before being able to form a new virion (Figure 3).
These sub-genomic sequences provide unique opportunities for the virus, mainly by enabling greater functionality out of a smaller original genomic sequence. They also present opportunities for tackling the pandemic. Sub-genomic RNAs are only present for virion formation during an active infection. As such, evidence from the University of Exeter showed they can be used to better track the infectivity and disease duration with SARS-CoV-2 infection, compared to the current wide-scale testing approaches.
Introduction to sequencing methods
The genomic era was propelled forward by DNA sequencing techniques pioneered by numerous scientists in the 1970s. Fredrick Sanger developed the “chain-termination method”, now known as the “Sanger method”, in 1977.
This method is based on a polymerase chain reaction (PCR) using labelled modified nucleotides (ddNTPs) that lead to a premature termination of the DNA chain extention. The result of chain-termination PCR is a considerable number of oligonucleotide copies of the DNA sequence of interest, terminated at random lengths by ddNTPs to be ordered in size using gel electrophoresis. The shortest fragment must terminate at the first nucleotide from the 5’ end, the second-shortest fragment must terminate at the second nucleotide from the 5’ end, and so on. As a result, by interpreting the gel bands from smallest to largest, the original DNA strand 5’ to 3’ sequence can be determined. The Sanger method recognizes up to 1000 bp DNA sequences in less than 2 hours. These findings epitomise what we now know as first-generation sequencing technologies. Watch the following video for details of the Sanger sequencing method.
This video is hosted by a third party
The next-generation methods used highly parallel sequencing approaches that were faster and cheaper (per base) with the ability to sequence hundreds of thousands to billions of DNA fragments per run. This may not always be the most efficient option however and will depend on what is being sequenced. Below we will describe the most commonly used Next-Generation Sequencing (NGS) technologies available.
Illumina Sequencing
After DNA is isolated, it is fragmented generally with physical (sonication) or enzymatic (Endonuclease-based) methods. A single adenine base is added to form an overhang via an A-tailing reaction onto the 3’ end. This allows adapters containing a single thymine-overhanging base to pair with the DNA fragments. The adapters are complementary to primers that are surface-bound to nano wells that help space out the genomic fragments and prevent overcrowding. Such primers act as anchors for the DNA fragments on both ends, forming a “bridge”. Bridge amplification is done by the polymerase generating two-stranded bridges. The two strands are separated, leaving a cluster of single-strand fragments. Fluorescently-labelled NTPs (dNTPs) are added to the single strands by the polymerase causing the elongation, the fluorophore blocks the synthesis preventing any other dNTP to bind. Every time a dNTP is bound to the strand, the computer records the colour of the fluorophore, and then the fluorophore is removed to allow synthesis to continue. The process is repeated until the sequence of the DNA fragment is obtained.
Ion Torrent
The Ion torrent technology is similar to Illumina but it differs in the way that fragments are added to microbeads and instead of recording a fluorophore, the addition of NTPs is identified with a voltage change in the cell measuring the pH change. Illumina and Ion torrent both have short read lengths (75-300bp with Illumina and 200-400bp with IonTorrent), but IonTorrent runs for only 2 hours compared to up to 56 hours with Illumina and has cheaper equipment. Illumina, on the other hand, has a lower error rate and a lower cost per base.
PacBio
This technology works with single-molecule real-time sequencing and uses nanocontainers with only one DNA molecule per hollow cylindrical well of 20 nm. The DNA molecule has to be prepared in a way that hairpin adapters are added to it to allow continuous circular sequencing. Once in the nanowell, dNTPs are incorporated one by one and the computer records the change of colour of each well. This technology yields long-read sequencing of more than 10 Kb with few systematic errors. It is ideal for de-novo assembly or long-range genomic structures. On the other hand, it also has a high single-pass error rate, to address this, coverage needs to be increased, resulting in an increase in cost and time, though even this extended time is still comparable to Illumina.
Oxford Nanopore Technology
Oxford Nanopore Technology (ONT) utilises nanopores through which a single-stranded DNA will pass. The nanopores are embedded in a membrane and a change of voltage is registered for each nucleotide in the strand that goes through the pore. It has unique features, like the ability to use a portable sequencer to bring to places that are hard to access; this makes it attractive since it facilitates viral genomic surveillance. Real-time sequencing also allows laboratories to stop when there is sufficient data. Using shorter amplicons and high mapping help to reduce the single pass error rate.
Further reading
WHO Guideline on SARS-CoV-2 genome sequencing
How is SARS-CoV-2 sequencing done?
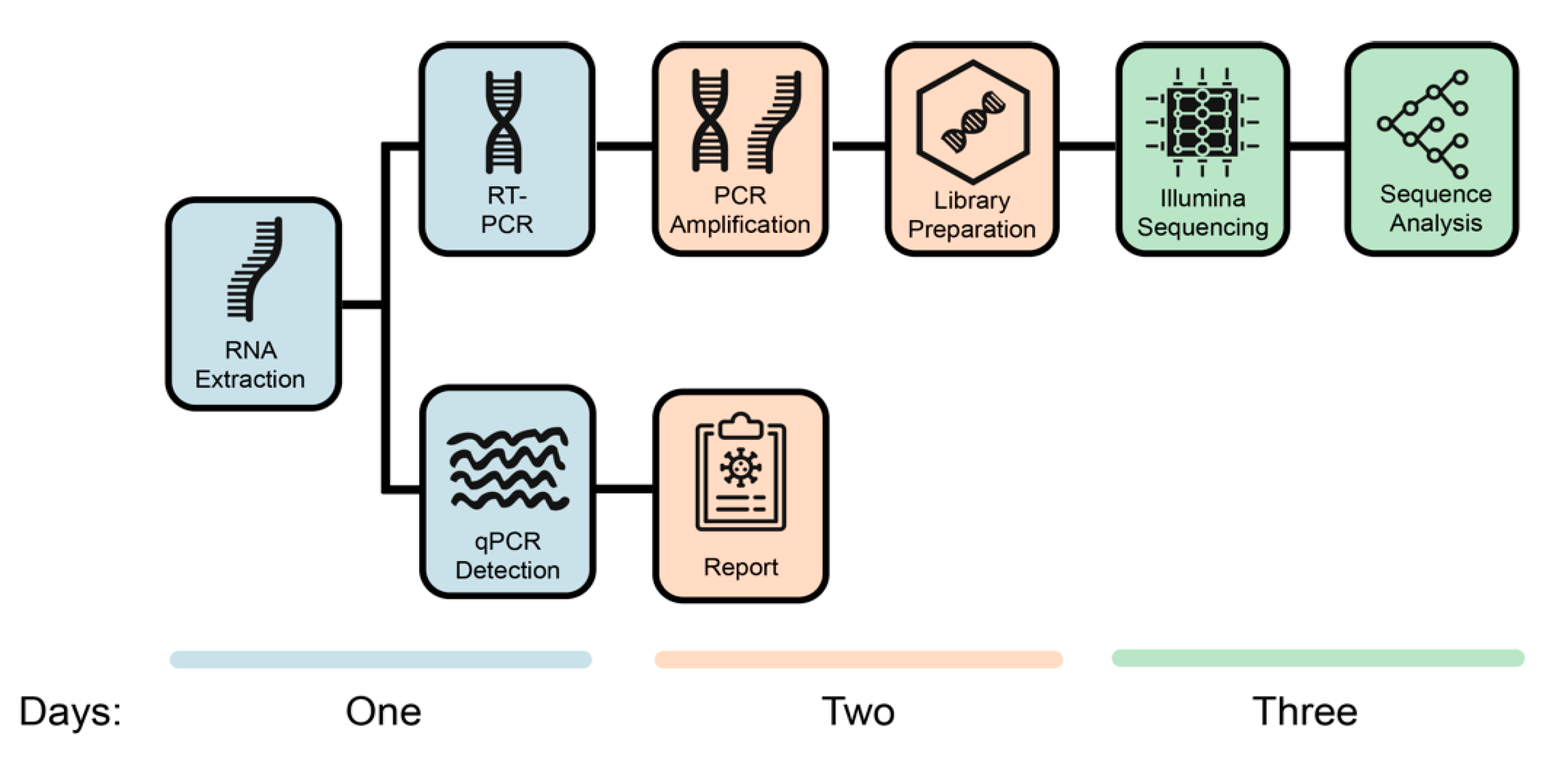
There are many sequencing technologies used for SARS-CoV-2 (Figure 4). Below, we will approach a broadly used protocol based on viral whole-genome sequencing (WGS). The method consists of viral RNA isolation, Library preparation, Sequencing run and Analysis.
Source: BMC Genomics
Click here to enlarge the image
Download Figure 4 alt-text here
Viral RNA Isolation
1. Viral inactivation
Sequencing of SARS-CoV-2 first requires inactivation of live virus either by heat or inactivating buffer so that the laboratory worker can handle the sample without putting themselves at risk. This procedure is carried out at various Biosafety Levels (BSL) worldwide. In the UK, prior to the current pandemic, this viral isolation would have been carried out at BSL3 facilities, but in early 2020, Public Health England issued a directive allowing this work to be completed at BSL2+.
2. Extraction of nucleic acid
The sample requires extraction of the nucleic acid so there is nothing else in the sample which could inhibit the sequencing. Extraction is normally performed by lysing (breaking down) the virus. Extraction can be performed using commercial kits or using magnetic beads to separate the nucleic acids from other materials in the sample. A range of buffers and alcohol suspensions are used to elute the nucleic acid into a final solution which is usually molecular-grade water.
Library preparation
1. Complementary DNA synthesis (not used for all technologies)
RNA extracts must be converted to cDNA because amplification methods, such as PCR, require DNA molecules as a template. A reverse transcriptase enzyme is used to synthesise the cDNA.
2. PCR Set-up and Amplification (not used for all technologies)
The cDNA is then added to a reaction mix including PCR reagents and SARS-CoV-2 specific primers, each targeting small regions of the viral genome. A specific primer targeting strategy is used to ensure that the entire genome is covered by these small regions. Samples are placed in a thermocycler, where amplification takes place. At the end of the process, millions of viral DNA fragments are generated.
3. Index PCR Set-up
NGS technologies allow multiplexing ie. pooling several different samples in a single sequencing run. In this process oligonucleotide indexes are added to each individual sample, ‘barcoding’ them, using a PCR procedure. This allows the individual samples to be separated computationally after sequencing.
4. Sample Pooling
The concentration of the DNA of the barcoded samples is measured and equal amounts of DNA of each sample are pooled in a single tube.
5. Clean-Up
NGS methodologies are highly sensitive. Inhibitors and reagent residues must be removed through DNA purification. It is strongly recommended to use magnetic beads purification protocols for the clean-up step.
Sequencing run
Depending on the technology used, the samples are loaded onto a flow cell and run on a sequencer that will generate fluorescent reads which can be captured by a camera or one which passes the entire molecule through a Nanopore and captures the sequence in real-time.
Analysis
Sequencing data is demultiplexed and the viral genome is assembled (similar to an alignment) using bioinformatics tools. There are many analysis pipelines, most commonly using command line, but there are also graphic interface tools.
SARS-CoV-2 ARTIC Protocols
There are specific ARTIC Network-derived protocols available for both Illumina
and Oxford
Nanopore Technologies platforms.
If you are interested in seeing a sequencing workflow in a laboratory, see this video (note, the video is silent) :
This video is hosted by a third party
Amplicon-based sequencing
Introduction
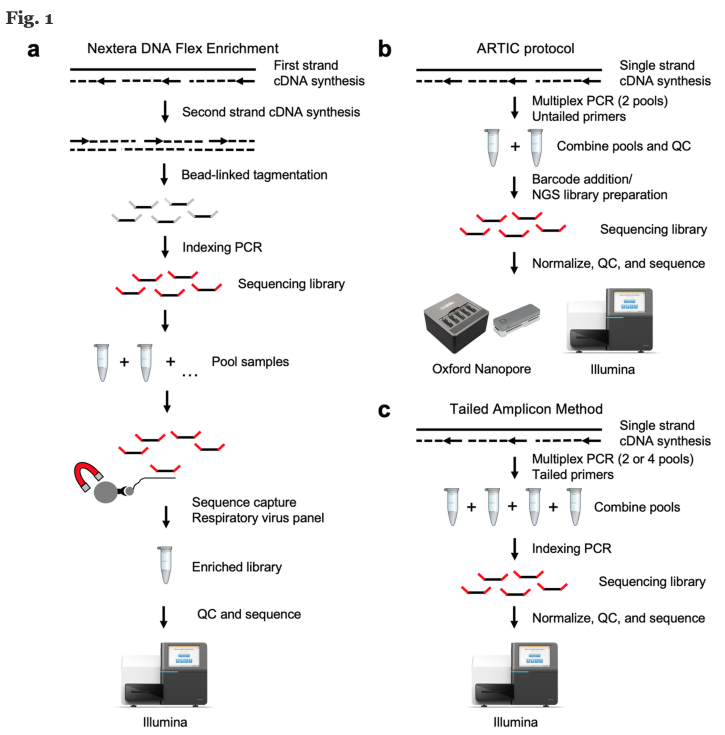
Amplicon sequencing is a highly targeted approach that enables researchers to analyse genetic variation in specific genomic regions. The ultra-deep sequencing of PCR products (amplicons) allows efficient variant identification and characterisation. This method uses oligonucleotide probes designed to target and capture regions of interest, followed by next-generation sequencing (NGS). SARS-CoV-2 whole-genome sequencing (WGS) requires a viral RNA isolation from the clinical samples for sequencing library construction, and there can be orders-of-magnitude differences in viral load across different subjects. A large proportion of clinical samples contain extremely low viral copy number, which may impact the quality of WGS (Figure 5).
Source: MDPI
{kind=link}
Click here to enlarge the image
Download Figure 5 alt-text here
The RNA viral genome is relatively small (~ 30 Kb) and highly heterogeneous. Due to these factors, the copy number of the viral genome is low and many errors can be introduced while sequencing after PCR enrichment. To overcome these hurdles, amplicon-based sequencing is utilised. In this method, the viral genome is amplified using primers which are complementary to known sequences. The amplicon enriched samples are then subjected to sequencing in platforms such as Nanopore or Illumina.
The ARTIC protocol is based on a method that enriches the cDNA generated through reverse transcription of the SARS-CoV-2 genome, using a tiled PCR amplification using two primer pools. A total of 196 primers (98 pairs) were designed to tile the entire SARS-CoV-2 genome. An amplicon size of ~400 bp per target is obtained that then moves to the specific library preparation either for Illumina or Oxford Nanopore sequencing (Figure 6).
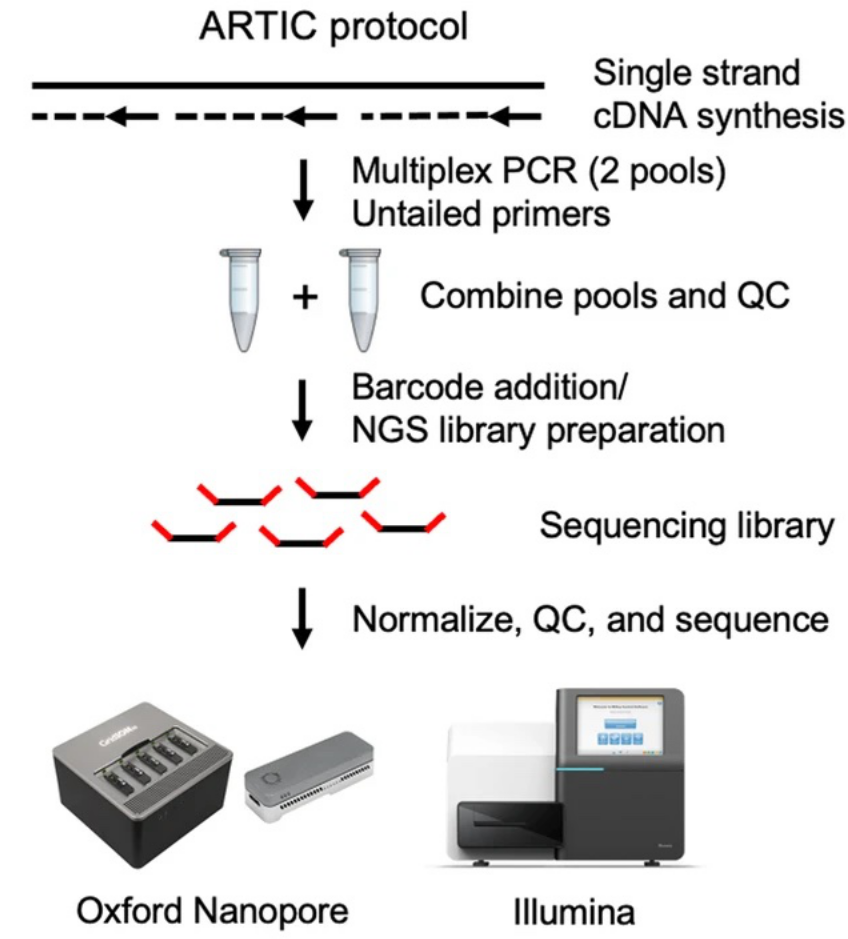
Source: BMC Genomics
Click here to enlarge the image
Download Figure 6 alt-text here
The Midnight protocol approach uses 1200 base pair (bp) tiled amplicons produced by the multiplex PCR. Briefly, two PCR reactions are performed for each SARS-CoV-2 sample which includes two sets of primers. The first set (Pool 1) has thirty primers that generate the odd-numbered amplicons, while the second PCR reaction has twenty-eight primers that generate the even-numbered amplicons (Pool 2). After PCR, the two amplicon pools are combined which can be further processed for sequencing using either Oxford Nanopore or Illumina platforms (Figure 7).
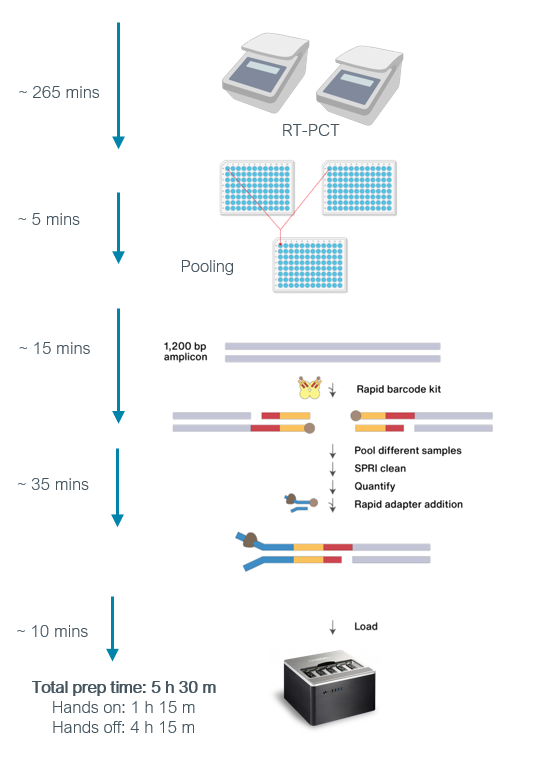
Source: Oxford Nanopore Technologies
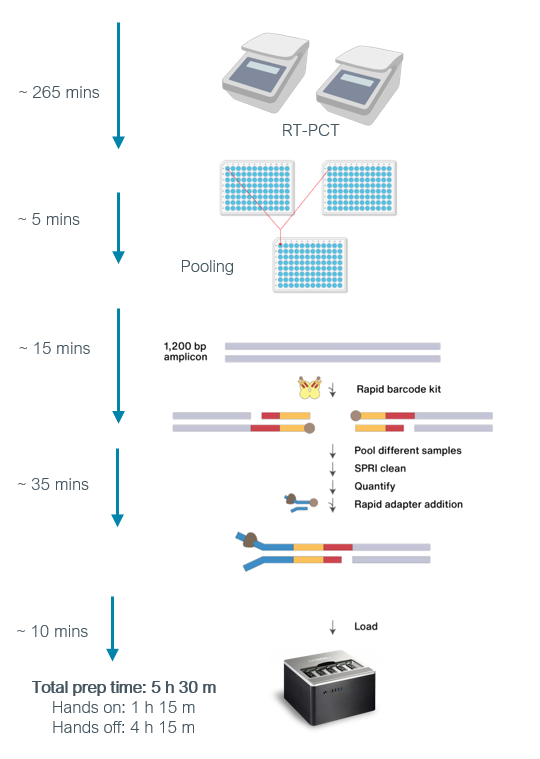{kind=link}
Click here to enlarge the image
Download Figure 7 alt-text here
Considerations for amplicon-based sequencing
- Enables researchers to efficiently discover, validate, and screen genetic variants using a highly targeted approach
- Supports multiplexing of hundreds to thousands of amplicons per reaction so that it can achieve high coverage
- Delivers highly targeted resequencing, even in difficult-to-sequence areas, such as GC-rich regions
- Allows flexibility for a wide range of experimental designs
- Reduces sequencing costs and turnaround time compared to broader approaches such as whole-genome sequencing
- Since primers cannot capture the very ends of the viral genome, amplicon approaches have the drawback of slightly less complete genome coverage, and mutations in primer binding sites have the potential to disrupt the amplification of the associated amplicon.
Further reading
Clinical and biological insights from viral genome sequencing
Overview of different data formats
Sequencing data can be saved in specific formats to make it easier to collect, store, analyse, and disseminate information. Each format will specify the manner in which each level of the genetic analysis is employed as it encodes the obtained information from each step of the pipeline, going from the sequencer data output, the alignment and all the way to the variant calling. The majority of data formats are text-based and can be explored using a simple text editor (apart from FAST5, which is specific to Oxford Nanopore Technologies and BCL files used in Illumina pipelines). Several technologies are attached to their own data formats, but there are several that are widely used in NGS data analysis. The data format flow in a typical NGS data analysis pipeline is generally composed of: FASTQ, BAM/SAM and VCF.
FASTQ
The format for sequencing data files known as FASTQ is based on text and may hold both raw sequence data as well as quality scores. A FASTQ file normally uses four lines per sequence: the first line begins with a ‘@’ character, the sequence identifier and an optional description; the second line has the raw sequence in letters; the third line, begins with a ‘+’ and has the same sequence ID and any description; and line 4 encodes the quality values for the sequence in line two.
BAM/SAM
After alignment, the file format that holds information on how our target sequence aligns to a reference is called SAM, which stands for Sequence Alignment/Map format. A BAM file is a binary compressed version of the SAM format, thus we refer to both formats as SAM/BAM. It is a TAB-delimited text format with an optional header section and an alignment section. Header lines begin with an ‘@,’ whereas alignment lines do not. Each tab acts as a separator between columns. A SAM file has 11 mandatory columns that hold information on each alignment, they hold information as follows: 1. Query template NAME, 2. bitwise FLAG, 3. Reference sequence NAME, 4. 1-based leftmost mapping POSition, 5. MAPping Quality, 6. CIGAR string, 7. Reference name of the mate/next read, 8. Position of the mate/next read, 9. observed Template LENgth, 10. segment SEQuence and 11. ASCII of Phred-scaled base QUALity+33. The optional fields must follow TAG:TYPE:VALUE, for them to be explicit and the information accessible for further analysis. After alignment comes variant calling.
VCF
The file format that holds variant calls information is called the variant call format or VCF. A single VCF file can hold many millions of variants. A VCF format is also a text-based, tab-delimited file. It contains meta-information lines that start with the characters ‘##’, a header that starts with only one ‘#’ and then data lines each containing information about a position in the genome. The format also has the ability to contain genotype information on samples for each position. It consists of 8 mandatory columns named in the header. These columns are as follows: 1. #CHROM: chromosome number, 2. POS: position, 3. ID: identifier of the variant, 4. REF: the reference allele, 5. ALT: the alternative allele, 6. QUAL: Phred-scaled quality score, 7. FILTER: filter status and, 8. INFO: additional information. The VCF can have more rows and columns, depending on how many samples are being analysed. One column is added for each sample, and one row is added for each variant or genotype that is found.
Further reading
Sequence Alignment/Map Format Specification
What is bioinformatics?
Paulien Hogeweg and Ben Hesper described for the first time the term bioinformatics as “the study of informatics processes in biotic systems”.
In a very simplistic way, bioinformatics could be defined as a field where computational science and biology meet. This subdiscipline uses interdisciplinary knowledge from computational science, mathematics, statistics, biology and genomics to analyse large amounts of biological data and to obtain knowledge from diseases, biological processes, evolutionary events, or any other question in life science. Computational biology is a similar term and refers to applying computational methods to solve biological problems (are they the same… the answer will change depending on who you are asking). What is crucial is that computational tools are key to biology and have shaped our understanding of doing biological research.
Computational methods have sped up the advances in biology by applying techniques developed in the past (e.g. hidden Markov models, principal component analysis), and creating new ones. Moreover, algorithms can be iterated and applied (like Bayesian inference, bootstrap) to large-scale experiments at different molecular levels (e.g. proteomics, epigenomics, metagenomics, any -omic), which can be used to shed light on specific biological questions. Computational techniques have been used to study mutational processes and led to the identification of mutational signatures related to cigarette smoke and UV light, as part of a large cancer study. They can also be used to organise information on the functions of genes (e.g. the GO ontology). Combining large collections of gene expression data into a cell atlas (e.g. collecting gene expression data of thousands of cells in different tissues at different stages of development in one database) enables identification of new cell types, a better understanding of how cells communicate and the pathology of disease.
Computational methods are useful when generating hypotheses, which is circular and iterative process.. Ideas can be tested in-silico, then hypotheses can be proven experimentally and new ideas may become apparent. Some researchers go further and model biological systems to make predictions in a way to understand the biological process and combine mathematical models, computational approaches, and biology knowledge.
Bioinformatics can be used for different and diverse applications. For example, analysing the regulatory mechanisms of gene expression and drug development; analysing ancient DNA of bacteria and viruses to infer co-evolutionary relationships and diet, and analysing ancient DNA to understand migration or inferring evolutionary history by modelling population bottlenecks with polymorphisms.
In fact, the field has evolved; it is more than just analysis, it requires integration of different data (multi-omics) to create inferences, and constant interdisciplinary development to learn and apply new knowledge and methods from outside of our field - leading to the emergence of data science.
Data science involves the following ideas:
Systems: which includes cloud environments, workflows, benchmarking, cybersecurity;
Design: how to communicate between computers and humans e.g. input data, visualisation of results;
Analysis: interrogating the data with different techniques for example deep learning, data mining, and statistical methods (be careful not to torture the data in doing so.
Value: the desired step of gaining knowledge. In the end, as Bourne, P. E also said “it really doesn’t matter what you call it. Just do it”. Others argue that “computational biologists are just biologists using different tools” and we should remove this label for avoiding segregation and bringing the community closer to solving biological questions.
Overview of web-based bioinformatics analyses using Galaxy
Donwload the presentation slides here This is a short introduction video explaining Galaxy servers and the tools available to do the bioinformatics analysis.
Importing data onto Galaxy
In this tutorial, you are going to learn how to access the Australian Galaxy server and upload data onto your account.
If you would like to try and test this tutorial on your own, you can use the example dataset available for download below. These are the raw reads of SARS-CoV-2 obtained by performing sequencing on Oxford Nanopore MinION using amplicon-based Midnight protocol primers.
You will find all the datasets for this course, including the one for this tutorial at the Zenodo repository.
Additional resources
Processing data on Galaxy
In this video, you will learn how to process your data on Galaxy using NanoPlot to assess the quality of the FASTQ files.
You will find all the datasets for this course, including the one for this tutorial at the Zenodo repository.
Building a workflow on Galaxy
By now, you are becoming familiar with the concepts of loading up an input file into Galaxy, performing a task with that file, and saving the output of this task. You will generally use one input file when learning about input file types and expected outputs. Once you are familiar with the flow of your system, you will need to introduce techniques to increase the “throughput” of your activities.
Throughput is a measurement of how many units of information a system can process in a given amount of time. A person selecting each subsequent step or operation will always have limited throughput. Computers, however, are excellent at repeating steps once these are configured. It is possible to scale up to massive computer clusters and data centres that can process terabytes of information in minutes.
Many data science tasks require the same processing or operations to happen to different input files. We will explore the “workflow” technique to explore the path of input and outputs of a series of tasks.
Galaxy has a workflow tutorial for building a workflow on the platform, and this was used to formulate the basis of this article. For more information, please explore the following resources:
Creating, Editing and Importing Galaxy Workflows (Galaxy Training Materials)
Community-Driven Data Analysis Training for Biology Cell Systems
To create a workflow, click on “Workflow” on the top panel in the Galaxy homepage, then see the “Create and Import” buttons on the top right, and click “Create”. Give your workflow a name - something memorable related to the task you wish to perform is best.
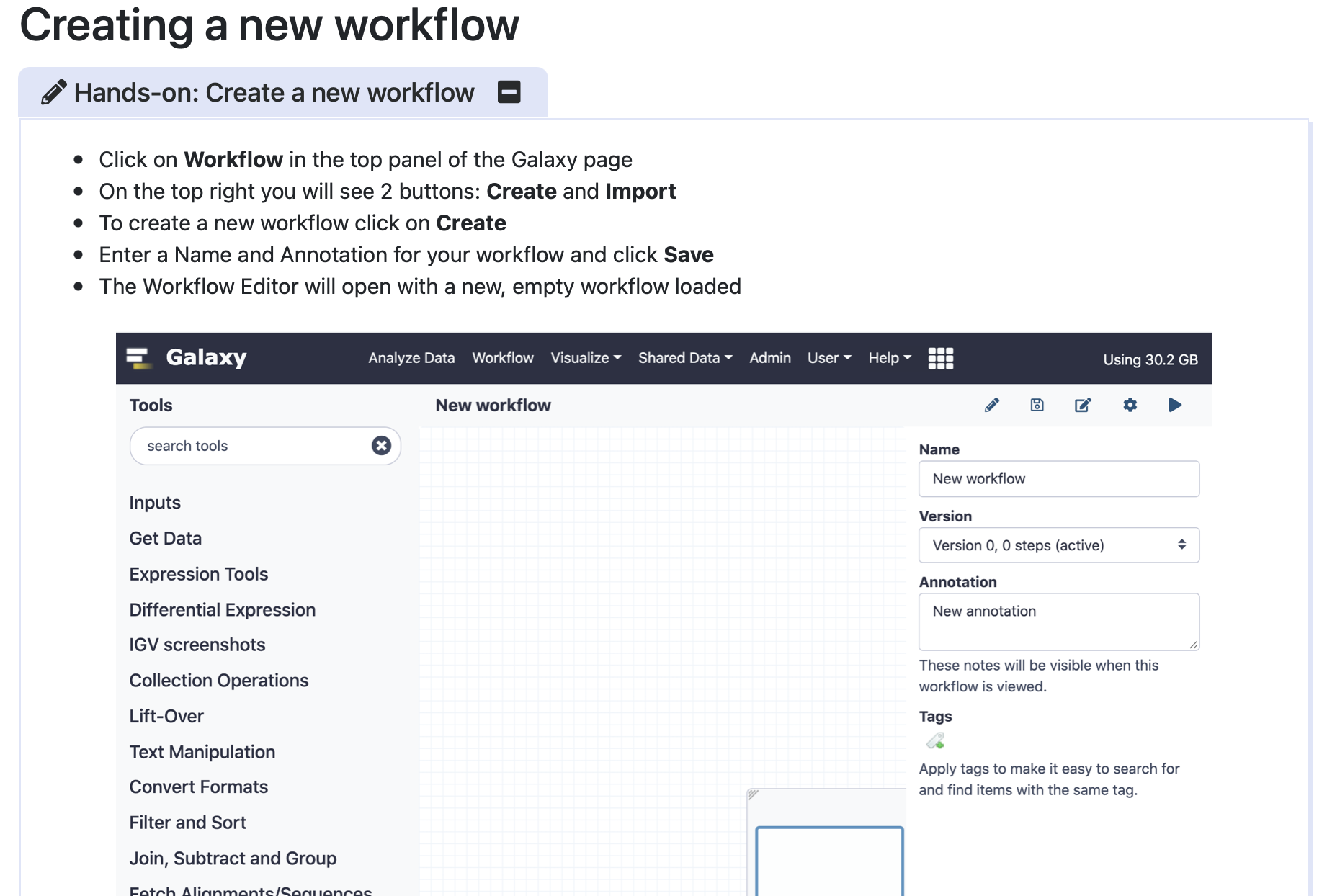
Click here to enlarge the image
Download Figure 8-16 alt-text here
In this example, we’ll make a workflow to flip a “digital burger”
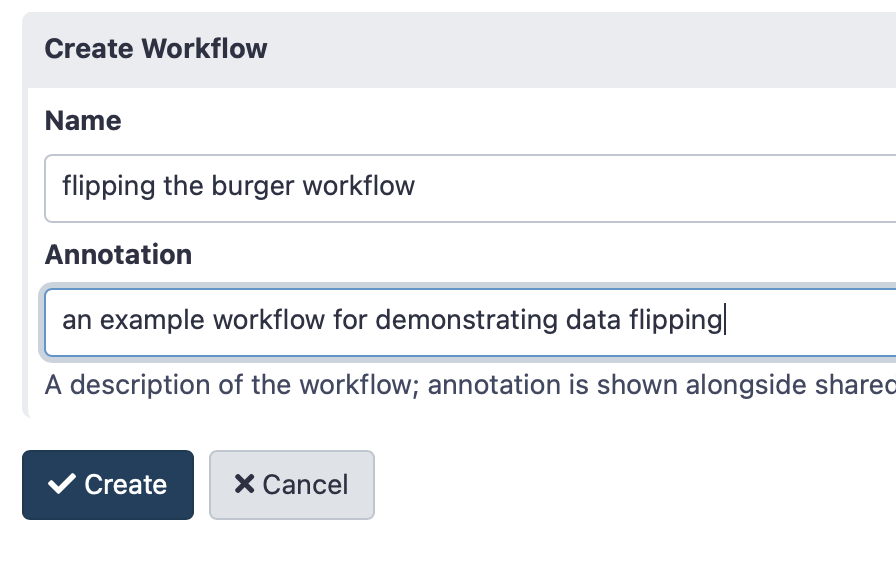
Click here to enlarge the image
After creating your workflow, you will see a blank canvas
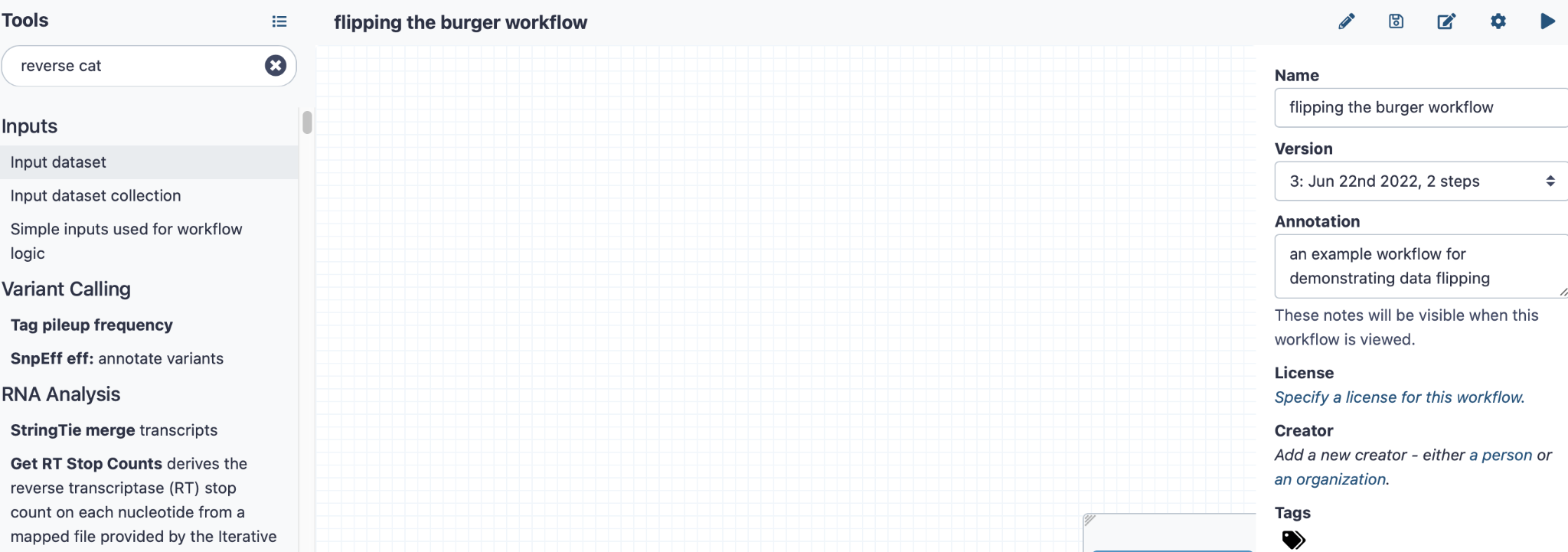
Click here to enlarge the image
You can add some annotations on the right-hand side panel to describe what this workflow does
On the left-hand side panel, click “Input Dataset”, and you will see a marker for this task on your canvas. Then you will be able to click on this to add some annotation data on the right-hand side panel
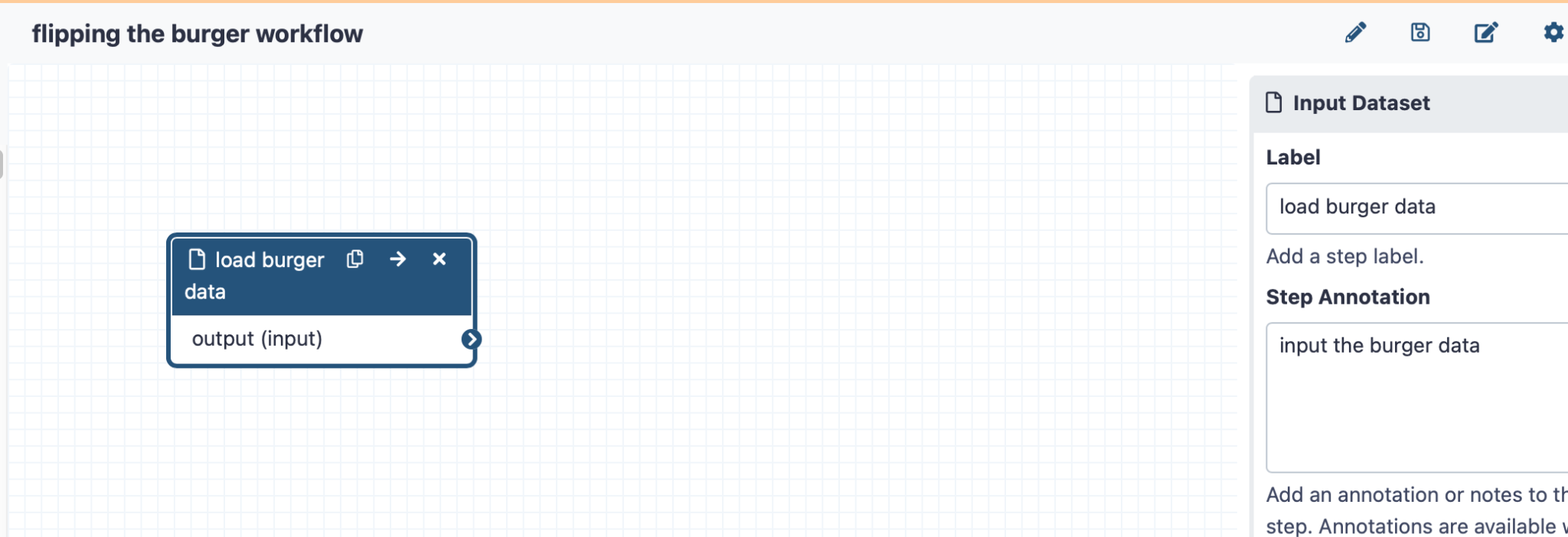
Click here to enlarge the image
Then add the tool “tac reverse a file” by searching for it on the left hand side panel
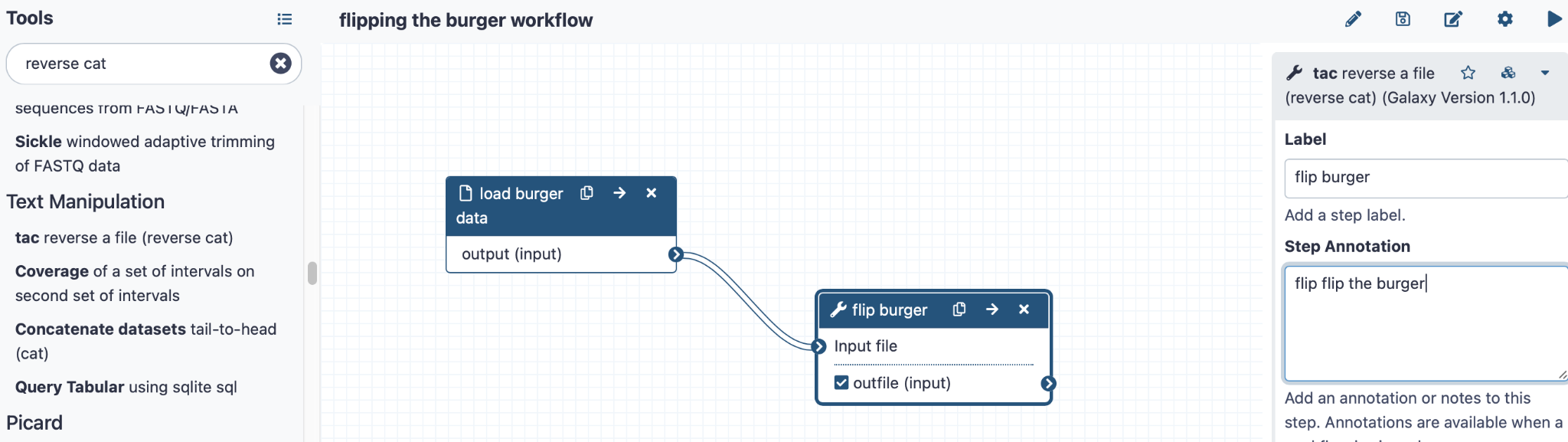
Click here to enlarge the image
You can add annotations for this too. Now link the two steps by dragging the small arrow “>” on the load burger step onto the arrow on the tac step (labelled flip burger).
Now click on the triangle in the top right corner to “run workflow”. You will see a page with the workflow name and an upload space for loading the “burger data” Click the vertical arrow on the right-hand side to initiate a file upload.
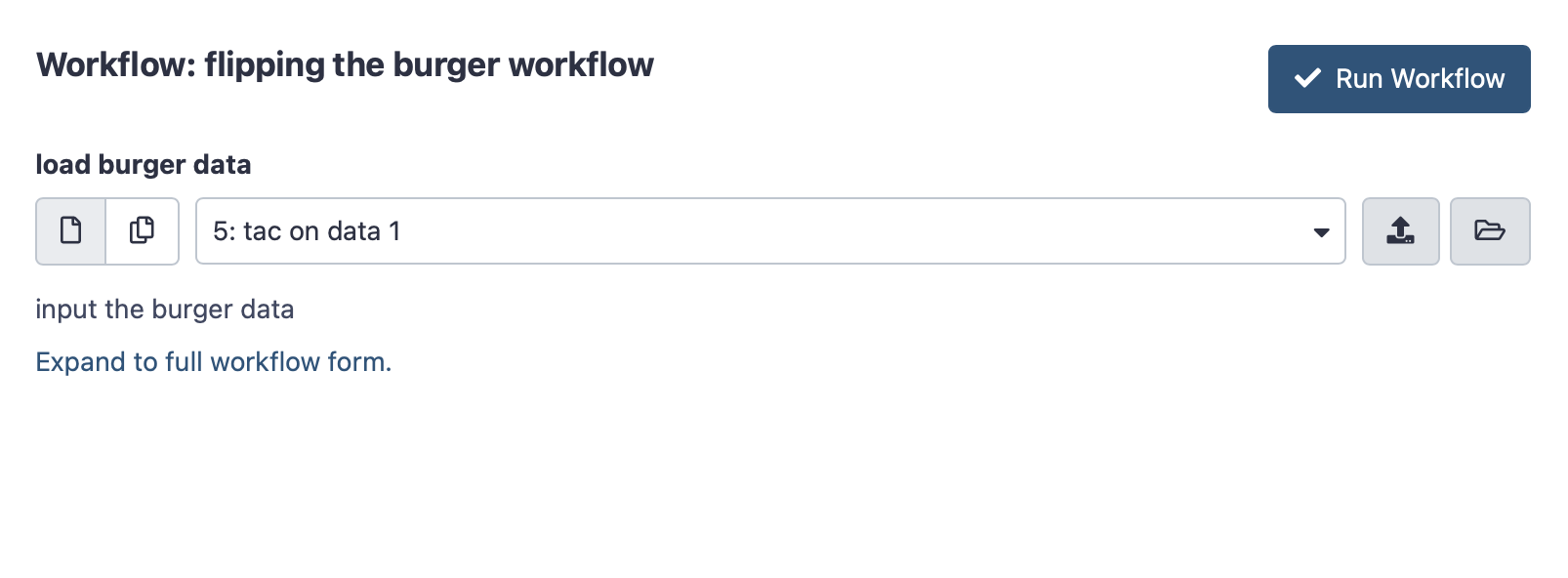
Click here to enlarge the image
Click here to enlarge the image
Select “Paste/fetch data”, then fill in the details - see examples below. You must add the name of the file, and the type (text file is format txt), then paste the lines of the “digital burger” as shown above. Once filled, click “Start”.
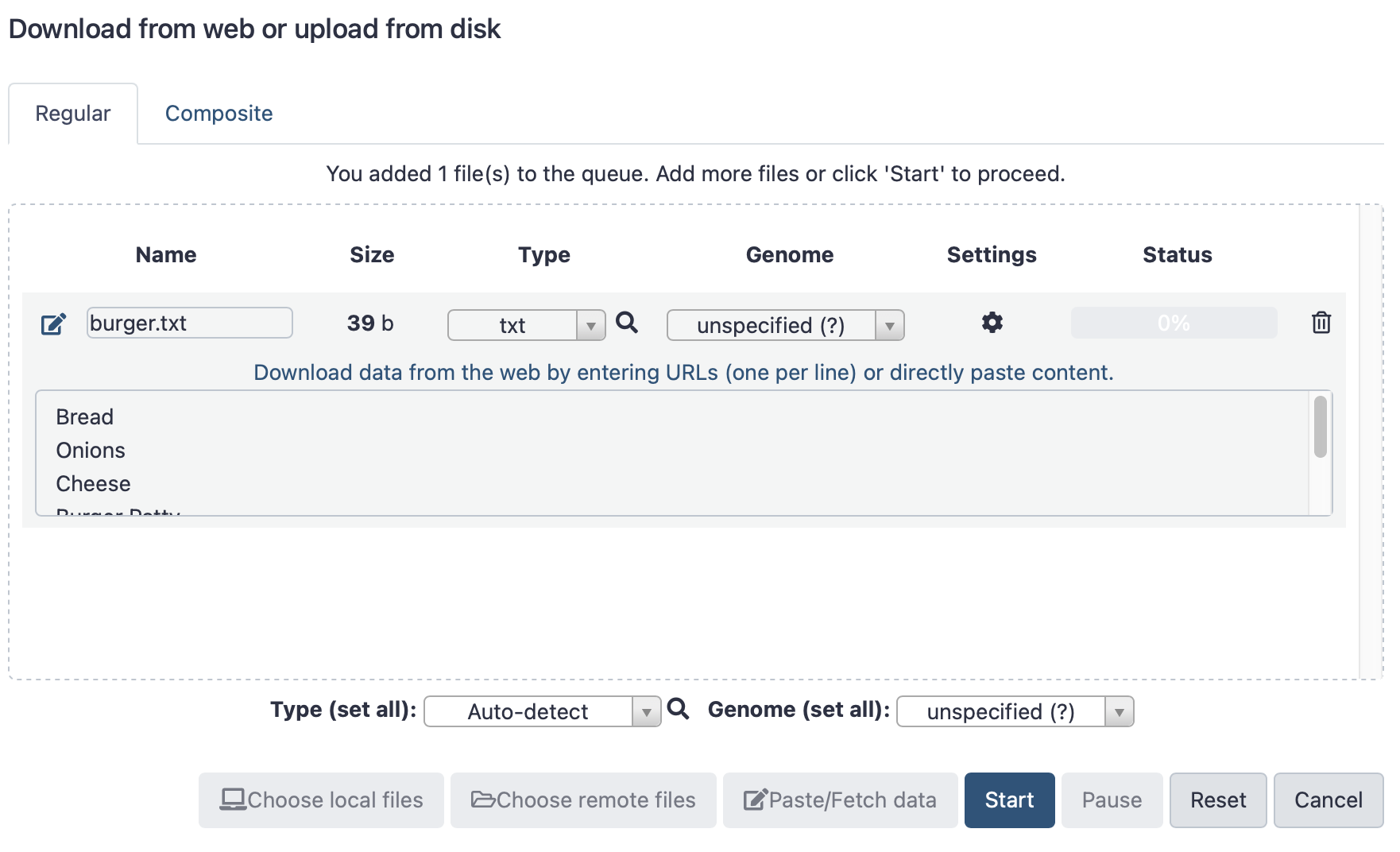
Click here to enlarge the image
You can then hit, “Start workflow”, and make sure the input file specified is the burger file you made (select it from the dropdown menu). Once the job is complete, you will see the output available via the history panel on the right.

Click here to enlarge the image
Our burger has been flipped! So now the order is:
Congratulations on making your first workflow! Now try to expand that workflow by trying to restore the order of the “burger”, add some ingredients into your input file, or try another tool to disassemble it!
Futher information
Using existing workflows on Galaxy
In this tutorial, you are going to learn how to import publicly available Galaxy workflows and execute them.
This workflow was edited from the original
workflow available on Galaxy to include Nextstrain and Pangolin to
assign lineage and clades. The workflow will run a series of tools to
generate outputs such as: Consensus FASTA (SARS-CoV-2 assembled
genome)
MultiQC Report
Clades and Lineages report
Variant file (SNPs)
Here we used the COVID-19 ARTIC analysis protocol to analyse the FASTQ files available at the Zenodo repository. To execute the workflow it is also required the BED file which contains the coordinates of the primers and the SARS-CoV-2 reference genome.